Systematisches Testen und Datenschutz im Einklang



Bereits mit dem aktuell geltenden Datenschutzgesetz (DSG) ist die Verwendung von Personendaten oder besonders schützenswerten Personendaten in Test- und Entwicklungssystemen rechtlich nicht zulässig. Deshalb sind in solchen Testumgebungen entsprechende Synthetisierungen oder Anonymisierungen von Daten für Testzwecke erforderlich.
Mit der Weiterentwicklung des Bundesgesetzes über den Datenschutz werden diese Rahmenbedingungen weiter verschärft. Die Gesetzesrevision war aufgrund der rasanten technologischen Entwicklung und der regulatorischen Entwicklung im internationalen Umfeld notwendig. Schliesslich machen Daten nicht an der Landesgrenze Halt. Das DSG wurde deshalb über die parlamentarischen Prozesse den veränderten Verhältnissen angepasst und am 25. September 2020 im Parlament verabschiedet. Damit werden insbesondere die Transparenz von Datenbearbeitungen verbessert und die Selbstbestimmungsrechte der betroffenen Personen über ihre Daten gestärkt. Die Totalrevision ermöglicht es der Schweiz, das revidierte Datenschutzübereinkommen des Europarats zu ratifizieren sowie die Datenschutzgrundverordnung (DSGVO) der EU im Bereich der Strafverfolgung zu übernehmen. Die Schweiz ist aufgrund des Schengen-Abkommens dazu verpflichtet.
In diesem Standpunkt erläutern wir, wie mit bewährten Methoden und Werkzeugen auf Basis von produktiven Datenbeständen datenschutzkonforme Testdaten für Entwicklungs- und Testprozesse erstellt und verwaltet werden können.
Mit der Digitalisierung werden Daten oft als «das neue Gold» bezeichnet. Entsprechend ist der notwendige Schutz der Daten auch ausserhalb produktiver System-Umgebungen sicherzustellen. Denn der Zugriff auf Produktionsdaten über Testprozesse ist beispielsweise für Mitbewerber durchaus interessant. Deshalb müssen Mechanismen und Werkzeuge zur Datenanonymisierung (DA) genutzt werden, um Kundendaten zu schützen. Mit einem angemessenen Testdatenmanagement (TDM) kann gewährleistet werden, dass Datenbestände während der Softwareentwicklung kontrolliert aktualisiert werden. Die Einhaltung der Datenschutzvorgaben wird hierbei durch verschiedene Anonymisierungs- und Synthetisierungs-Massnahmen erreicht.
Um die Einhaltung der DSG-Vorgaben bei vernetzten Systemen zu prüfen, sind neben den allgemeinen Grundlagen des DSG und der EDÖB-Leitlinien auch die fallspezifischen Gesetzesgrundlagen einzubeziehen.
- Personendaten: Name, Vorname, Geburtsdatum, Adresse, Wohnort
- Besonders schützenswerte Personendaten: politische Ausrichtung, Gesundheit, Religion
Die Bearbeitung von Daten ausserhalb von produktiven Systemen bedeutet oft, dass die in der Produktion genutzten technischen und organisatorischen Massnahmen nicht zur Anwendung kommen. Der Datenschutz ist dadurch möglicherweise nicht angemessen sichergestellt.
Aus datenschutzrechtlicher Sicht ist die Bearbeitung von produktiven Personendaten beziehungsweise besonders schützenswerten Personendaten in Entwicklungs- und Testsystemen in dieser Form nicht zulässig. Der Schutz der Daten ist mittels Anonymisierung in allen Systemumgebungen sicherzustellen – hierzu sind die angemessenen technischen und organisatorischen Massnahmen zu treffen. Die Vorgaben dazu sind im auf Gesetzesstufe im DSG Art. 7 sowie detaillierter in der Datenschutz-Verordnung (VDSG) in Art. 8ff dokumentiert.

«Der Schutz von Testdaten ist eine wichtige Kompetenz, die Unternehmen erlangen müssen. Denn schützenswerte Daten können auch aus Testsystemen missbräuchlich verändert, kopiert oder entwendet werden.»
Rolf Bühlmann, Co-Autor und Testdatenmanagement-Experte
Testdatenmanagement sorgt für kontrollierte Prozess
In der Praxis wird in Projekten oder agilen Entwicklungen oft in pragmatischer Art und Weise mit einer Kopie von produktiven Daten getestet. Um den Datenschutz auch in Testumgebungen zu erhöhen, sollte man sich mit den Themen Testdaten und Testdatenbereitstellung befassen.
Als Grundlage ist es wichtig zu sehen, dass es sich bei Testdaten nicht einfach «nur» um anonymisierte oder synthetisierte Datensätze handelt. Testdaten stellen Datensätze in definierten Datenkonstellationen dar, die für die Ausführung von definierten Testfällen benötigt werden. Alle wichtigen Aspekte rund um Testdaten sind in einem Testdatenmanagement (TDM) zusammengefasst. Das Testdatenmanagement beinhaltet konzeptionelle und methodische sowie organisatorische und technische Massnahmen und Verfahren, um Testdaten zu bewirtschaften. Das Testdatenmanagement ist eng mit dem Testmanagement und dem «Application Lifecycle Management» verbunden. Es beinhaltet eine Vielzahl von Aspekten wie Anonymisierung, Synthetisierung, Bereitstellung, TDM-Tools sowie Betrieb und Support.
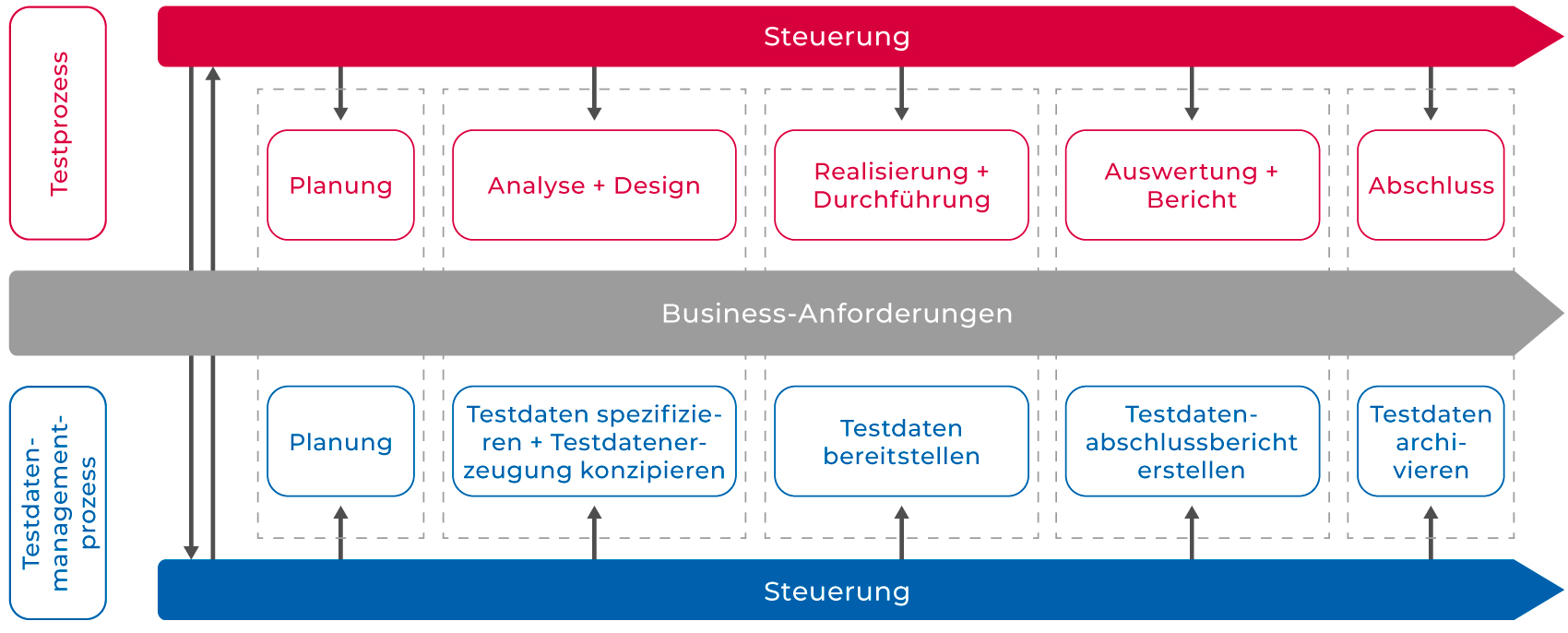
Abbildung 1: Zusammenspiel des Testprozesses und des Testdatenmanagementprozesses
Systemkontext ermöglicht Übersicht
Als Grundlage einer Testsystem-Konzeption ist in einem ersten Schritt das relevante System inklusive aller für eine Anonymisierung relevanter Schnittstellen zu definieren und grafisch darzustellen. Damit wird sichergestellt, dass alle am Anonymisierungsprozess beteiligten Personen oder Organisationen ein identisches Bild nutzen. Damit wird das Anonymisierungsvorhaben verständlich vermittelt.
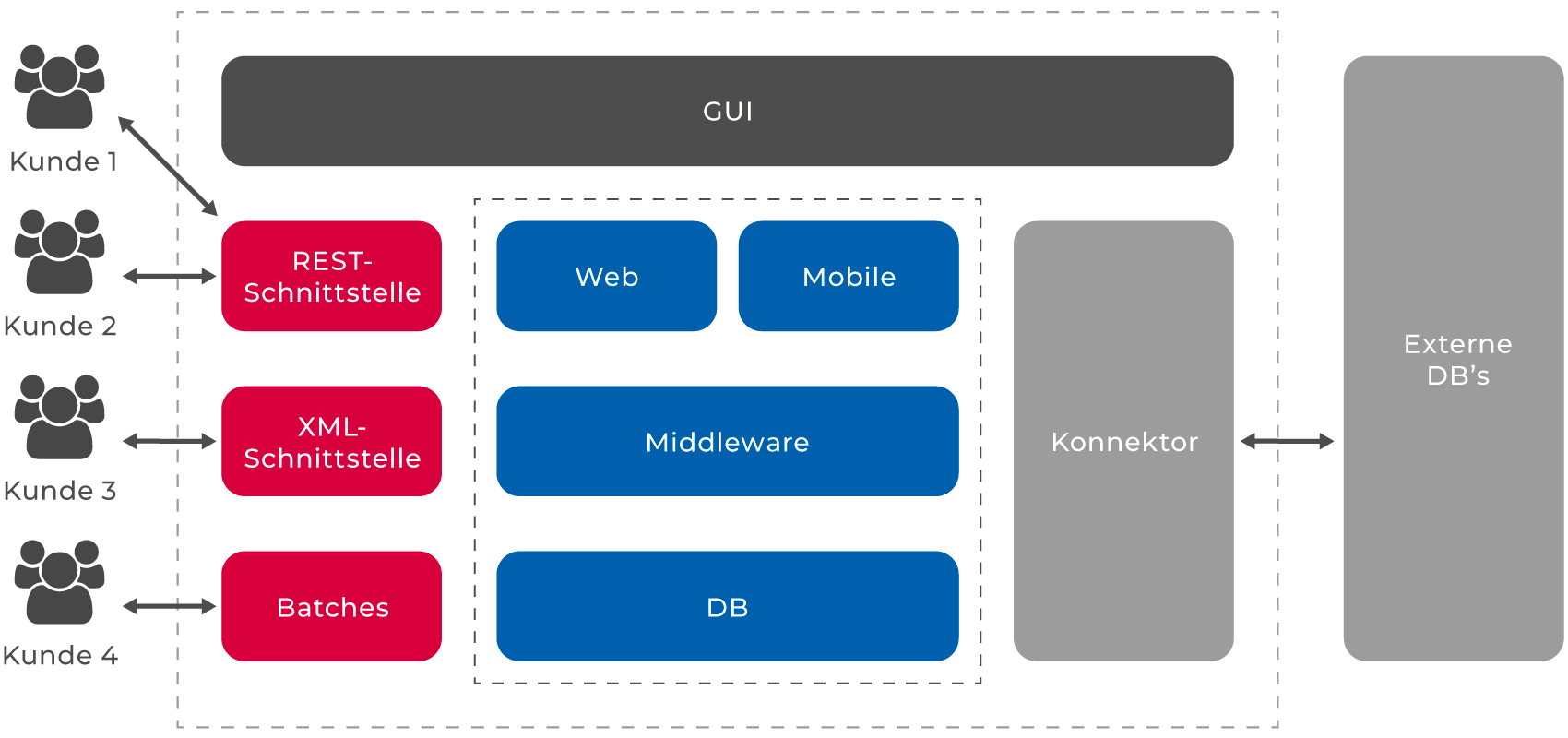
Abbildung 2: Beispiel eines Systemkontexts mit unterschiedlichen Schnittstellen
Testdatenmanagement aufbauen
Auf der einen Seite steht das Testdatenmanagement mit Ansprüchen an den Datenschutz, die Testdatenqualität und die Verfügbarkeit von Testdaten. Auf der anderen Seite stehen die Kunden bzw. Nutzer, das sind in Projekten die Fachbereiche, die Entwicklung und das Testing. Nur wenn die Anforderungen an die Testdaten verständlich sind, kann davon ausgegangen werden, dass auch die Erstellung und Nutzung von anonymisierten Testdaten möglich ist. Der Aufbau des Testdaten-Managements erfolgt typischerweise in mehreren Etappen. Bevor mit der Implementierung eines Testdatenmanagements gestartet wird ist es wichtig, sich mit der angestrebten Maturitätsstufe auseinanderzusetzen. Die untenstehende Tabelle erläutert die einzelnen Reifegradstufen von 1 bis 5 mit zunehmender Komplexität. Die Stufen sind in einem entsprechenden TDM-Konzept zu entwickeln.
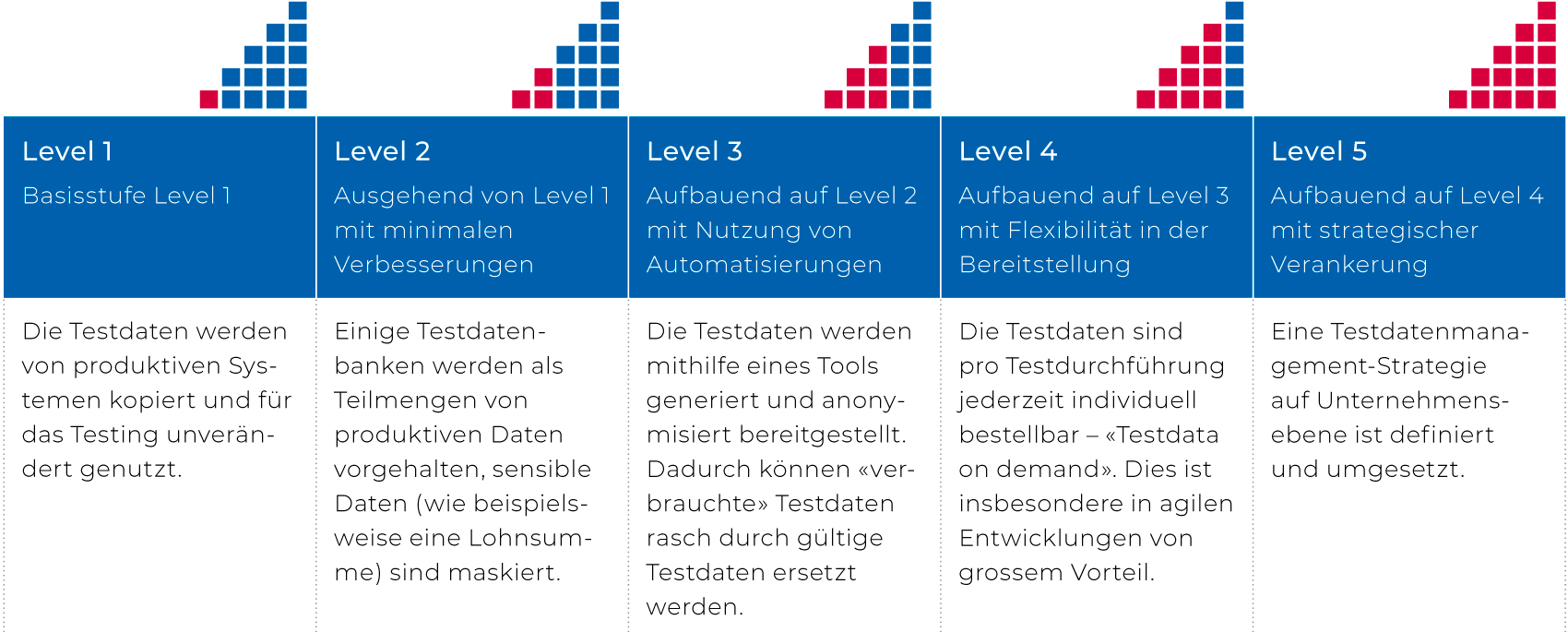
Abbildung 3: Die einzelnen Reifegradstufen einer Testmanagementstrategie von Level 1 bis 5 mit zunehmender Komplexität
Die Erreichung eines vordefinierten Maturitätslevels hängt von verschiedenen Faktoren wie Zeitplan und verfügbaren Ressourcen (personell und finanziell) ab. Bei strategischen Projekten, kürzeren Releasezeiten oder wenn agile Methoden und DevOps-Modelle integriert werden sollen, wird mindestens ein Maturitätslevel 4 benötigt. Optimal sollte Level 5 angestrebt werden, um die Agilitätsziele erreichen zu können.
Testdaten und anonymisierte Daten sind unterschiedlich
Betrachten wir Testdaten und anonymisierte Daten näher, so sind wesentliche Unterschiede festzustellen. Anonymisierte Daten und ein Testdatensatz im Testsystem differenzieren sich dadurch, dass die Testdaten eine definierte Funktion im Testprozess haben und eindeutig einem oder mehreren Testfällen zugeordnet sind. Die anonymisierten Daten dagegen haben keine eindeutige Funktion im Testsystem und sind keinem Testfall zugeordnet. Jeder anonymisierte Datensatz kann zum Testdatensatz werden, wenn die eindeutige Zuordnung zu einem Testfall oder einer Funktion im Testsystem erfolgt ist.
Testdaten synthetisieren oder anonymisieren?
Die Datenschutzanforderungen an Testdaten können mit Anwendung von anonymisierten und/oder mit synthetisierten Daten erfüllt werden.
Anonymisieren beinhaltet die Veränderung von personenbezogenen Daten, sodass die einzelne Angaben über persönliche oder sachliche Verhältnisse nicht mehr oder nur mit einem unverhältnismässig grossen Aufwand (Zeit, Kosten und Arbeitskraft) einer bestimmten natürlichen oder juristischen Person zugeordnet werden können. Die Anonymisierung basiert auf der Verwendung von produktiven Daten.
Bei synthetischen Datensätzen werden die Daten mit definierten Verknüpfungen und Werten neu und unabhängig von den aktuellen produktiven Daten angelegt. Synthetische Daten und anonymisierte Daten unterliegen in der Folge sehr unterschiedlichen Herausforderungen und Risiken.
Wenn es der Zweck des Projekts zulässt, sollten vorzugsweise anonymisierte Daten verwendet werden. Anonymisierte Daten fallen nicht mehr unter das Bundesgesetz über den Datenschutz. Ist die Anonymisierung nicht möglich, kann mit pseudonymisierten Daten gearbeitet werden. Weitere Details dazu sind im «Leitfaden technische und organisatorische Massnahmen des Datenschutzes» des EDÖB ersichtlich.
«Sensible Daten in Testsystemen sind risikoreich. TDM Tools ermöglichen effiziente Datenanonymisierung und effektives Testdatenmanagement.»
Rolf Bühlmann, Co-Autor und Testdatenmanagement-Experte
Daten analysieren und nach DSG beurteilen
Grundsätzlich sind alle Personendaten, die sich gemäss Definition in DSG, Art. 3 lit. a.) auf eine bestimmte oder bestimmbare Person beziehen, zu anonymisieren. Damit fällt die Bearbeitung des betreffenden Datensatzes nicht in den Geltungsbereich des DSG. Bestimmbar ist eine Person dann, wenn ein Rückschluss auf sie aufgrund des Kontexts möglich ist. Beispielsweise durch indirekt identifizierende Informationen wie eine Benutzernummer, eine IP-Adresse, Standortdaten, biometrische Daten oder anderweitige identifizierende Angaben oder Identifikationsmerkmale. Nachstehend soll erläutert werden, wie man die Frage: «Was muss anonymisiert werden?» entsprechend beantworten kann. Dazu wird zunächst der Umfang der Anonymisierung bestimmt. Dieser ergibt sich aus der Verbindung der vorhandenen Daten und den Anforderungen des DSG. Die weiteren Schritte sind:
- betroffene Daten mittels «sensitive Daten Discovery» identifizieren
- für jedes erkannte Identifikationsmerkmal wird der Umgang mit bestimmten Datentypen für die Anonymisierung festgelegt
Das «sensitive Daten Discovery» bezeichnet das Verfahren zur Untersuchung von Datenstrukturen auf sensitive und sensible Daten. Dabei werden direkte und indirekte Identifikationsmerkmale über die gesamte Dateninfrastruktur hinweg gesucht und identifiziert.
- Direkte Identifikationsmerkmale: Daten lassen direkte Identifizierung zu
- Indirekte Identifikationsmerkmale: Daten, welche in Verbindung mit anderem Wissen eine Identifikation ermöglichen
- Nicht identifizierende Daten: Alle anderen Daten, die weder direkte oder indirekte Identifikationsmerkmale darstellen
Identifikationsmerkmale anonymisieren
Die Identifizierung von Identifikationsmerkmalen übernimmt der hierfür verantwortliche Testdatenmodellierer. Er verantwortet die Analyse der Identifikationsmerkmale und die Planung der Anonymisierung im Detail.
Bei der Analyse und der Planung ist es wichtig zu berücksichtigen, dass bei jeder Anonymisierung die referenzielle Integrität, welche zwischen Identifikationsmerkmalen herrscht, beachtet werden muss.
Für die Anonymisierung ist für jeden sensiblen Datentyp durch den Testdatenmodellierer, welcher exemplarisch die Anonymisierung vorbereitet, die Definition der Datenveränderung festzulegen. Anschliessend wird der Testdatenproducer diese in Anonymisierungsroutinen umsetzen.
Testdatenmanagement (TDM) Tools verwenden
Die Testdatenmanagement Tools gewährleisten ein nachvollziehbares End-to-End-Testdatenmanagement. Dies ist für die effiziente Bereitstellung von Testdaten in vernetzten Systemen sinnvoll.
Spezifische Tools bieten beispielsweise auch Funktionen zur Datenmaskierung, Datenunterteilung und zur synthetischen Datenerzeugung. Diese werden oft kombiniert mit einer Vielzahl weiterer länderspezifischer Algorithmen für die Datenanonymisierung. Dabei gilt es, die referenzielle Datenintegrität in allen gängigen Datenbankformaten zu berücksichtigen. So unterstützen diese Testdatenmanagement Tools die Einhaltung der Datenschutzvorgaben im Unternehmen.

«Produktionsdaten stellen eine wertvolle Grundlage für Testdatenbestände dar. Eine zunehmende Sensibilisierung der Kunden und sich verschärfende datenschutzrechtliche Grundlagen in Bezug auf die Verwendung von produktiven Daten in nicht produktiven Systemen verunmöglichen diese Praxis in Zukunft. Die Lösung besteht darin, auf Basis von produktiven Datenbeständen über bewährte Methoden und Tools der Anonymisierung und Synthetisierung von sensiblen Datentypen einen rechtskonformen Testdatenbestand zu erzeugen und zu verwalten. Dieser Datenbestand trägt wesentlich zur Risikoreduktion von missbräuchlicher Datenverwendung bei, da keinerlei Rückschlüsse auf real existierende Personen oder besonders schützenswerte Daten ermöglich sind.»
Stefan Lenz